My Pet Grimalkin
Well, I’m back. And after nearly two years of no activity on this blog, what incredible spectacle do I have prepared for you, my irrationally loyal reader? Introducing CatGPT, the Catenated Grimalkin Program Talker. As stupid as it sounds, I spent a lot of time with the thesaurus to come up with that name, so please let me have this. Naming things is hard.
CatGPT is a simple AI chat bot that uses Markov chain-based text prediction to generate responses, and it seems to have suspiciously specific knowledge about just one thing… cats. So like, do you get it now? Grimalkin is an old word for cat, you see. And if you think that’s silly then you try googling “synonyms for cat that start with G, P, or T” and see if you can do better. On second thought, you might want to skip the “P” search. Anyway, catenate is a word containing “cat” that also happens to mean “to link together”, which fits well with the Markov chain theme, so yea, this name is actually very clever, and it’s you who’s spent too much time thinking about it.
Where was I? Oh yes, CatGPT isn’t just a blatant attempt to capitalize on the current popularity of some other chat bots out there, it’s one that we’re going to build together! I guess to be more clear, this is a tutorial where I’ll walk you through how to build a text generation tool using simple Markov chains and dress it up a bit to be something we can talk to. Obviously we won’t be blowing any LLMs out of the water here, but hopefully we’ll learn some things along the way about probability, natural language, and Python development.
Markov chains and language
In a fairly abstract sense, text generation comes down to answering the question: how do I decide what to say next based on what was said before? Language, after all, is not completely random; it contains structure (grammar, syntax, diction) that emerges as correlations in the text. Certain characters are more likely to follow certain other characters, which are more likely to be arranged in certain orders and appear in certain places, and so on. This correlation structure is what allows language to carry information, such that the reader can parse that information using his or her own understanding of the structure. In general, natural human language is messy and imprecise, and the actual information content of a piece of text is highly complicated, involving correlations that aren’t necessarily local. One of the things that makes ChatGPT so powerful is its ability to capture and reproduce these correlations at many scales, allowing for text that feels holistic and sensible from start to finish.
We, however, will start from a humble place and focus on the kind of text generation where what we say will depend only on what was just said, roughly speaking. It is this property that will make our model Markovian, i.e. the probability that we produce a character \(c\) will depend only on the previous \(k\) characters in the text. You might think that we need to restrict ourselves to looking at only one previous character to be truly Markovian, but it turns out the number of characters doesn’t really matter (in fact, we could do the same thing with whole words or even more abstract “tokens”, if our source text were rich enough). What matters is that our next character is influenced by a sequence of previous ones, not that sequence and some other sequence from a couple paragraphs back, for example. In this way, one sequence influences the next sequence, which influences the next sequence, and so on such that all the sequences of length \(k\) are probabilistically linked together, which is what makes this a Markov chain.
We can visualize the chain as a graph, where each node is a “state” that is a \(k\)-length sequence, and each edge represents the probability that the next state (after adding a character and sliding the window over) will be some other \(k\)-length sequence.
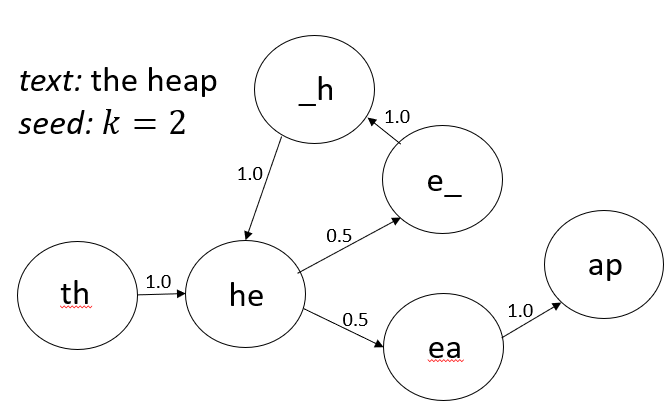
So, we’ll call \(k\) the kernel size and call the output (single character) of our model \(y\). Then, given an input \(x\) that is a string of \(k\) characters, we want to compute the probability \[ P(y = c | x)\quad \forall c\in\mathcal{A} \] Here, \(\mathcal{A}\) is the alphabet for our model, the set of all the possible characters we’re allowed to produce. In our case this happens to also be all the unique characters that appear in our source text. Once we have this probability in hand, we’re golden. For a given \(x\), we have a probability distribution over all possible choices of \(c\). All we need to do is pick a character at random according to that probability, spit it out, and repeat.
The trick, of course, is that we need to somehow compute this probability. In our case, this will be done by simply counting occurences in the original text, such that our generated text will have the same correlation structure as the source, for whatever \(k\) is pre-selected.
Developing the code
For this project, we’re going to use Python (for now). It’s worth noting that there are powerful tools out there for manipulating text and processing natural language, such as NLTK, but we’re going to mostly avoid those for this project and do things ourselves.1 We’ll start by building up the three main ingredients of our model:
- Building the probability distribution from the source text
- Generating new text
- Making it interactive
Building the distribution
There are different ways to go about this, but the first idea I had turned out to be easy to implement and perfectly adequate in efficiency. The idea is to use nested dictionaries to create a lookup table for character frequencies. The outer dictionary’s keys will be sequences of \(k\) characters, each one pointing to an inner dictionary of characters pointing to their frequencies.
def build_lookup(source_text, k):
lookup = dict() # the outer dictionary
for i,_ in enumerate(source_text):
if i+k >= len(source_text): # make sure you don't go out of bounds
break
x = source_text[i:i+k] # x, the current sequence of k chars
y = source_text[i+k] # y, the next char that appears
if x not in lookup: # if this is the first time we've seen x, add it
lookup[x] = {y: 1}
else:
if y not in lookup[x]: # count the number of times y appears after x
lookup[x][y] = 1
else:
lookup[x][y] += 1
return lookupThe loop creates a sliding window, our \(k\)-sized kernel, that scans over the source text and counts up the number of times different characters follow. Now, when we access this lookup dictionary with some input x, what we get back is the probability distribution we were after. Of course, really what we get is a distribution of frequencies, and we’d need to divide these by the total number of occurences to get probabilities, but this is an unnecessary step, as we’ll see later. Python’s random.choices function allows us to use the raw frequencies as weights to get the desired result.
Generating new text
It almost seems too good to be true, but generating new text is similarly pretty straightforward. What we need is a desired length for the new text, a seed from which to start adding characters, and the lookup table that we built from before. We just pick new characters from the lookup inner dictionary weighted by their frequencies (which are the values in that dictionary).
import random
def generate_text(lookup, k, length, seed):
text = seed
for i in range(k, length):
x = text[i-k:] # current input, starting with seed
chars = list(lookup[x].keys()) # the chars to choose from
weights = list(lookup[x].values()) # the frequencies with which those chars appeared in source
next_char = random.choices(chars, weights=weights, k=1)[0]
text += next_char
return textIt’s really that simple. By the way, random.choices returns a list, so with k=1 we’re telling it to return one character, but we still need to grab the \(0\)th element to access it.
Now would be a great time to run a little test to see if things work. For now, let’s take just the first paragraph from the Wikipedia page for cat and use that as source text.
source_text = 'The cat (Felis catus) is a domestic species of small carnivorous mammal. It is the only domesticated species in the family Felidae and is commonly referred to as the domestic cat or house cat to distinguish it from the wild members of the family. Cats are commonly kept as house pets but can also be farm cats or feral cats; the feral cat ranges freely and avoids human contact. Domestic cats are valued by humans for companionship and their ability to kill rodents. About 60 cat breeds are recognized by various cat registries.'
k = 1
lookup = build_lookup(source_text, k)
seed = source_text[:k]
new_text = generate_text(lookup, k=k, length=100, seed=seed)
print(new_text)Executing the above (\(k=1\)) gave me:
Thed t bus famo inivats It dond avavamby mmis. acon by 60 f tis hegicon tst wie ican d t omarouivous
If we crank \(k\) up a bit, to say \(k=5\), we get something a little more English sounding:
The cat ranges freely and their ability to kill rodents. About 60 cat ranges freely and their abilit
Our bot seems a bit confused and is repeating itself, but that’s just because of how small our source text is. If you’d like, you can throw an even shorter source text in there, like “hello there”, and print out the lookup table to convince yourself of what it’s doing. This can be useful for debugging.2
Making it interactive
As a final step, we’d like to make this text generation code something we can actually interact with. In the spirit of mimicking ChatGPT, we envision a setup where we can ask the bot something, and have its response in some way incporporate what we asked. Furthermore, we’d like to rinse and repeat this to have an ongoing conversation.
Let me be clear: we’re not getting fancy here. The beloved CatGPT that we’re building is… special. The goal here is to be a bit goofy, so we’re going to make this interactive in quite a dumb way. But more on that later.
First, let’s fill CatGPT’s brain with a lot more info, specifically all the Wikipedia pages in the category “Cats”. The general and proper way to scrape data from the web would be to use a combination of the requests and beautifulsoup packages, but we can get away with even more simplicity by using the wikipediaapi package. If we want to extend our bot to learn from other online sources in the future, we’d need to go the former route.
So let’s write a function that takes a category name and grabs the content for all the pages that are in that category.
import wikipediaapi
def load_wiki(category):
wiki = wikipediaapi.Wikipedia('en', extract_format=wikipediaapi.ExtractFormat.WIKI)
cat_page = wiki.page(category)
article_names = [p for p in cat_page.categorymembers.keys() if ':' not in p]
content = ''
for article in article_names:
page = wiki.page(article)
page_content = page.text
content += page_content
return content.replace('\n', ' ')The one subtlety to point out here is in the line article_names = [p for p in cat_page.categorymembers.keys() if ':' not in p]. We’re excluding page names that contain “:” in them because we don’t want to deal with the recursive nature of Wikipedia categories. To keep things simple, we’re only going to scrape the pages that sit directly in the “Cats” category, and this line of code seems to do the trick.
Now the final step. We need to:
- Build our lookup table using the source text scraped from the Wikipedia articles
- Ask the user for some input
- Parse the input to extract “keywords” to then search for in the source text
- Randomly select a \(k\) sized seed from the text based on this keyword search
- Generate a response using that seed
- Repeat
Ok maybe I got a bit ahead of myself when I said “final step”. Steps 3 and 4 here seem like a head scratcher, so let’s spell out a little more clearly what they mean. Again, I want the user’s input to somehow influence the response by CatGPT, and the simplest way I could think to do this was to search the source text for instances matching words in the user’s input and use that as a seed to generate the response.
Two issues immediately arise from this approach. First, we don’t want to waste our time looking for common words and articles, so we’re going to use a dictionary of stopwords from nltk.corpus to filter out such words, leaving us with more interesting “keywords”. Second, we need our seed to be of length \(k\), so some padding around the keywords will be needed to make sure whatever sequences we find are the correct length. Then we’ll just pick one at random and go from there.
Finally, the code to do all this is below. There are some small tricks here and there, like using regex and string translation to filter out punctuation, prepending our keywords with spaces to avoid finding matches in the middle of words, and some others. But instead of going through every trick, I encourage you to take this code and play around with it yourself to uncover all its quirks. Again, for a project like this it is absolutely necessary to continually unit test, try your best to break it with nontrivial inputs, and generally mess around with it until you can shake all the bugs out.
import re
import string
import nltk
from nltk.corpus import stopwords
def run_catGPT():
# load text from all the Wikipedia pages on cats
source_text = load_wiki('Category:Cats')
# use nltk to download the set of stopwords
nltk.download('stopwords')
stops = set(stopwords.words('english'))
# set kernel size. I'm a fan of k = 10
k = 10
# build probability distribution as lookup table
lookup = build_lookup(source_text, k)
print('\nHello, my name is CatGPT. What can I help you with today?')
while True:
# request user input, and exit if the user says goodbye
input_text = input('\n> ')
if input_text.lower() == 'goodbye':
break
# get a list of the user's words, ignoring punctuation, then filter out the stopwords
words = re.findall(r"[\w']+|[.,!?;]",
input_text.lower().translate(str.maketrans('', '', string.punctuation)))
keywords = list(filter(lambda w: not w in stops, words))
# for each keyword, find matches in the text and pad them to be of length k
# add them to a list of potential seeds
seeds = []
for w in keywords:
for match in re.finditer(' ' + w, source_text):
s = match.start() + 1
e = match.end()
padded = source_text[s:e]
if len(padded) > k:
seeds.append(padded[:k])
else:
while len(padded) < k:
e += 1
padded = source_text[s:e]
seeds.append(padded)
# if for some reason no match was found, set the seed as start of text
if not seeds:
seed = source_text[0:k]
else:
seed = random.choice(seeds)
# generate a response of length 500 (or whatever you want)
response = generate_text(lookup, k, length=500, seed=seed)
# do some post-processing to make sure the response ends with a period and starts capitalized
last_period = response.rfind('.')
if last_period == -1:
last_period = len(response)
response += '.'
response = response[0].upper() + response[1:last_period+1]
print('\n' + response)A conversation with CatGPT
The following is a conversation I had with CatGPT. Enjoy.
Hello, my name is CatGPT. What can I help you with today?
Hi CatGPT. Do you have any cat fun facts for me?
Cats and free-ranging domestic and wild cats descended from domestic cat with a large area entirely unsuitable for breeding have red eyes. The point gene allele is a single cat found with intact males, while spayed female cat”, also used to call a cat. The myth is attributed to the slaughter.
Jesus, that got kind of dark at the end
Darkest of all the boarding catteries. In 2007 market surveys showed that 67% of the mice killed by feral cats may chase. Reproduction. These lineages include pain and swelling around the mid 950s BC onwards. At the times at which a kitten becomes difficulties in distinguishable from domesticated cats. Along with rabbits, some sea birds, and sheep, form the entire growth cycle of contraction and establishment, but the current wildcat population. There are various methods for training the cat.
I didn’t really understand most of that, but yes training a cat is what I want! I’d love to train my cat
Cats. Young orphaned and how long they were embalmed, coffined and buried in cat cemeteries for mummies offered to Bastet.In the mid 19th century. It was suggested that the earth was experience poor growth and can result in retinal degenerations could reach them only with a small cat species, a factor that has been identified as a domestic cats (mostly unowned) are the top human-caused threat to wildlife, transmission of illness.
Oh, I see. That’s pretty bleak. Also, I’m beginning to suspect you’re not really that smart
Also neurological cell types. White cats and other animal welfare. The cat will produce black eumelanin based) fur, caused by the abandonment of pets. The usefulness of TNR are often funded by big businesses to combat the city’s cemetery of Beni Hasan necropoli were reused as cemeteries at the locus. Other genes white markings allow point coloration are more frequent in the palace in order to optimize the link between two of the remote village is accessible from Houtong Station of the cat gap.
Closing remarks
Well, this has been genuinely fun. Our little chat bot may not be the sharpest tool in the shed, but he’s certainly… something. A bit darker in tone than I expected.
The code for this project can be found on my Github here.
Thanks for getting through this with me, if you’ve made it this far. Next time around we’ll take this one step further, by building a Flask web app for our beloved CatGPT, hosting it using Google Cloud’s App Engine, and building a JavaScript frontend so that all can enjoy his depressing cat facts on this site. It’s gonna be fun.
Footnotes
The official reason for this is so we can get our hands dirty and also keep things transparent, but it is also true that I’m just not an expert on NLP and wasn’t aware of these tools when I set out to do this. Regardless, for our relatively simple application we really don’t need anything too fancy.↩︎
I’m leaving out a lot of the steps that it took to actually get all this working. As in all coding projects, periodic, systematic testing is key to finding bugs and catching nasty corner cases. If I chronicled all of that here this post would never end.↩︎